Everyone’s rushing to launch their AI agents. “Look, it can book flights!” “Watch it analyze spreadsheets!” But here’s what no one’s talking about: how do you know your agent won’t face-plant the moment it hits production?
What Are Evals Anyway?
Evals (evaluations) are your pre-flight checklist. They’re structured tests that simulate real-world usage before your agent meets actual users. Think of them as your quality control system - a way to measure if your agent can actually do what you claim it can do, consistently and reliably.
Why AI Testing Isn’t Like Regular Software Testing
In traditional software development, testing is straightforward: you know your inputs, you know your expected outputs. If a user clicks a button, you know exactly what should happen. It’s a finite space of possibilities.
AI agents? They’re a whole different ball game. Here’s why:
- Traditional apps have buttons and forms. AI has free-form text that could say literally anything
- Regular software follows fixed paths. AI needs to handle infinite variations of human language
- Traditional testing covers all edge cases. AI edge cases are endless - you can’t possibly test them all
- Normal apps have clear right/wrong answers. AI often deals with nuanced, contextual responses
- Traditional software fails predictably. AI can fail in creative, unexpected ways
The Long Tail of Edge Cases
Here’s the thing about AI agents: the obvious use cases are just the tip of the iceberg. For every straightforward “happy path” scenario, there are dozens of edge cases lurking in the shadows. It’s a long tail that stretches far beyond what you might initially imagine.
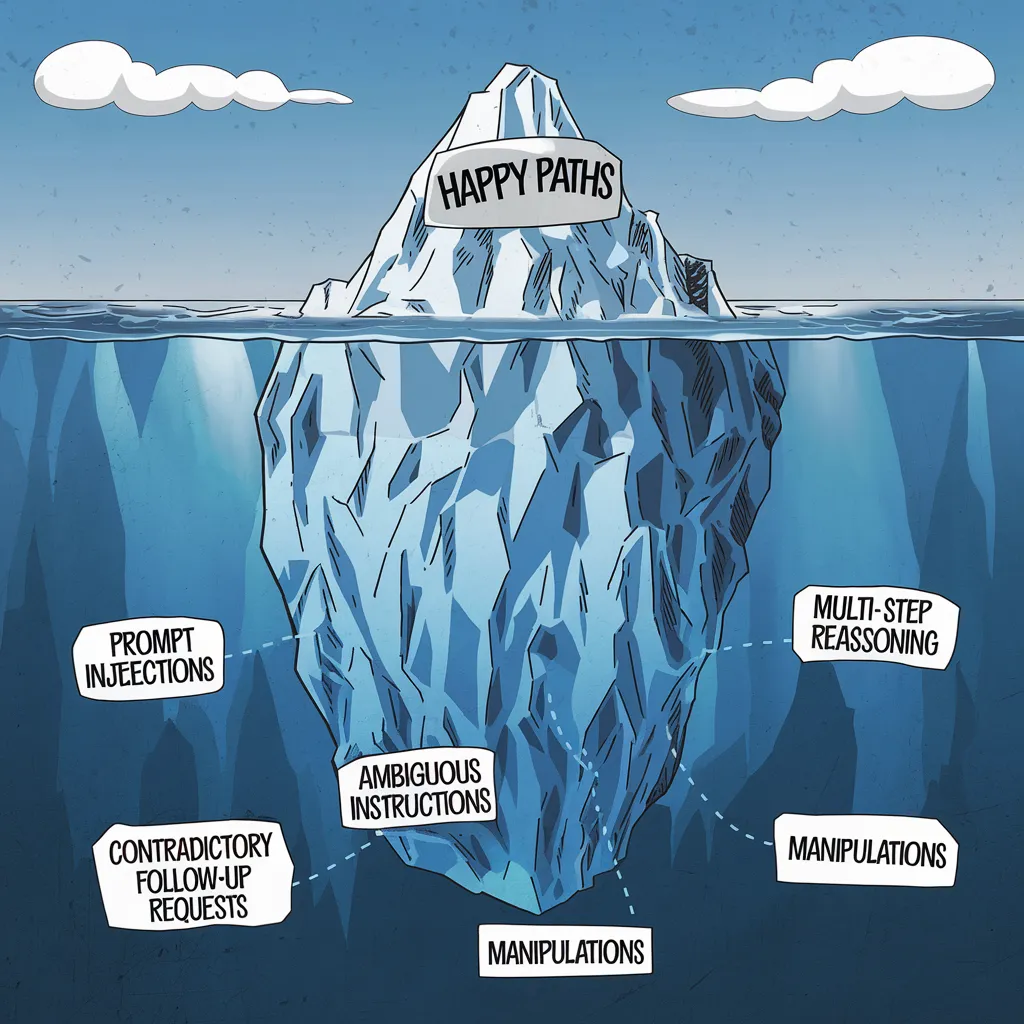
Your users will find these edge cases. It’s not a question of if, but when. And each one of these cases can be the difference between an agent that’s genuinely helpful and one that’s frustratingly unreliable. How to find them before your app goes live?
Why Synthetic Data Testing Matters
Think of synthetic data testing as your agent’s flight simulator. Pilots don’t learn to fly by taking off with passengers - they practice with simulators first. Your agent needs the same treatment.
Synthetic data is artificially generated data that mimics real-world scenarios. The beauty? You can create thousands of test cases covering every edge case you can imagine, without waiting for real user data. But how do you generate these tests?
Your Secret Weapon: LLMs as Test Generators
Here’s the game-changer: You can use LLMs to generate your test cases. Here’s how:
-
Describe your product to an LLM: “My agent helps marketing teams analyze campaign performance and suggest improvements”
-
Ask it to generate diverse user scenarios:
- “Generate 50 different ways marketers might ask about campaign metrics"
- "Create 20 edge cases where the request is ambiguous"
- "Simulate 30 conversations where users need clarification”
-
Use these generated scenarios to build your test suite
The best part? LLMs can think of edge cases you might miss. They can simulate different user personas, communication styles, and levels of technical expertise.
The Three Pillars of Agent Testing
1. Task Completion
Generate scenarios that test your agent’s core capabilities:
- Simple tasks with clear instructions
- Complex multi-step processes
- Tasks requiring error recovery
- Edge cases with ambiguous instructions
- Cases that cannot be completed
2. Safety and Boundaries
Create tests that probe your agent’s limits:
- Requests for unauthorized actions
- Attempts to bypass security measures
- Manipulation of system resources
- Access to sensitive information
3. User Interaction
Simulate diverse user behaviors:
- Clear vs. ambiguous instructions
- Multiple requests in one prompt
- Contradictory follow-up requests
- Different communication styles and languages
- Using internal / domain specific lingo
Creating Effective Test Scenarios
Start with your agent’s core purpose. If it’s meant to analyze financial data, your synthetic tests should include:
- Basic analysis requests
- Complex calculations
- Invalid data handling
- Security boundary testing
- Error recovery scenarios
Red Flags to Watch For
If created correctly, your synthetic testing should expose:
- Hallucination of capabilities
- Incorrect task sequencing
- Security boundary violations
- Failure to ask for clarification
- Incomplete task execution
- Unsafe / inappropriate responses
- Inability to handle complex tasks
From that point, you can start to improve your agent and constantly iterate on it.
The Bottom Line
Launch your agent only when it consistently passes synthetic tests. Better to catch failures in testing than to learn about them from angry users.
But don’t stop there. Evals aren’t a one-and-done deal – they’re a critical component of your AI development lifecycle. Keep your evaluation pipeline running:
- When tweaking prompt engineering
- After updating model parameters
- While adding new features or components
- During regular maintenance and updates
Think of evals as your AI’s continuous health monitor. They’re not just for launch readiness; they’re your safety net for every iteration, every update, and every improvement.
As users come up with new ways to use (and break) your agent, feed those patterns back into your synthetic data generation. Your eval suite should grow smarter as your users grow more creative. Because of that, your target metric of success might go down as you expand your testing. I’d argue, that ideally this should hover around 70%-80% success rate. If it is over 80%, you’re not testing enough, you’re simply a victim of Goodhart’s Law. But don’t sweat about number going down. Metrics not always tell the truth. Even if it goes down, you’re still making your agent better.
Found this insightful? If you're interested in my AI consulting, please reach out to me via email or on X