I’m seeing an interesting juxtaposition lately. While many people claim we’re observing a downfall of the software quality and speed, it is also a well-known fact that optimizing your website speed is crucial for your business’ success. Just a second of delay affects user engagement and lowers your business KPIs significantly. There’s a big contrast between what’s delivered and what’s expected.
We are trying to bridge this gap by throwing money using solutions like Vercel, Netlify or CloudFlare, which deploys our websites to the globally available CDNs to fix the latency problem, but oftentimes speed of these websites is limited by the slowness of related APIs or specifically, how far our requests have to travel through the internet to reach the public endpoint. Paradigms like JAMStack, which try to eliminate the need to interact with APIs, are definitely step in the right direction. However, they are not a remedy. Some use cases just won’t fit that model, you might still need a classical backend.
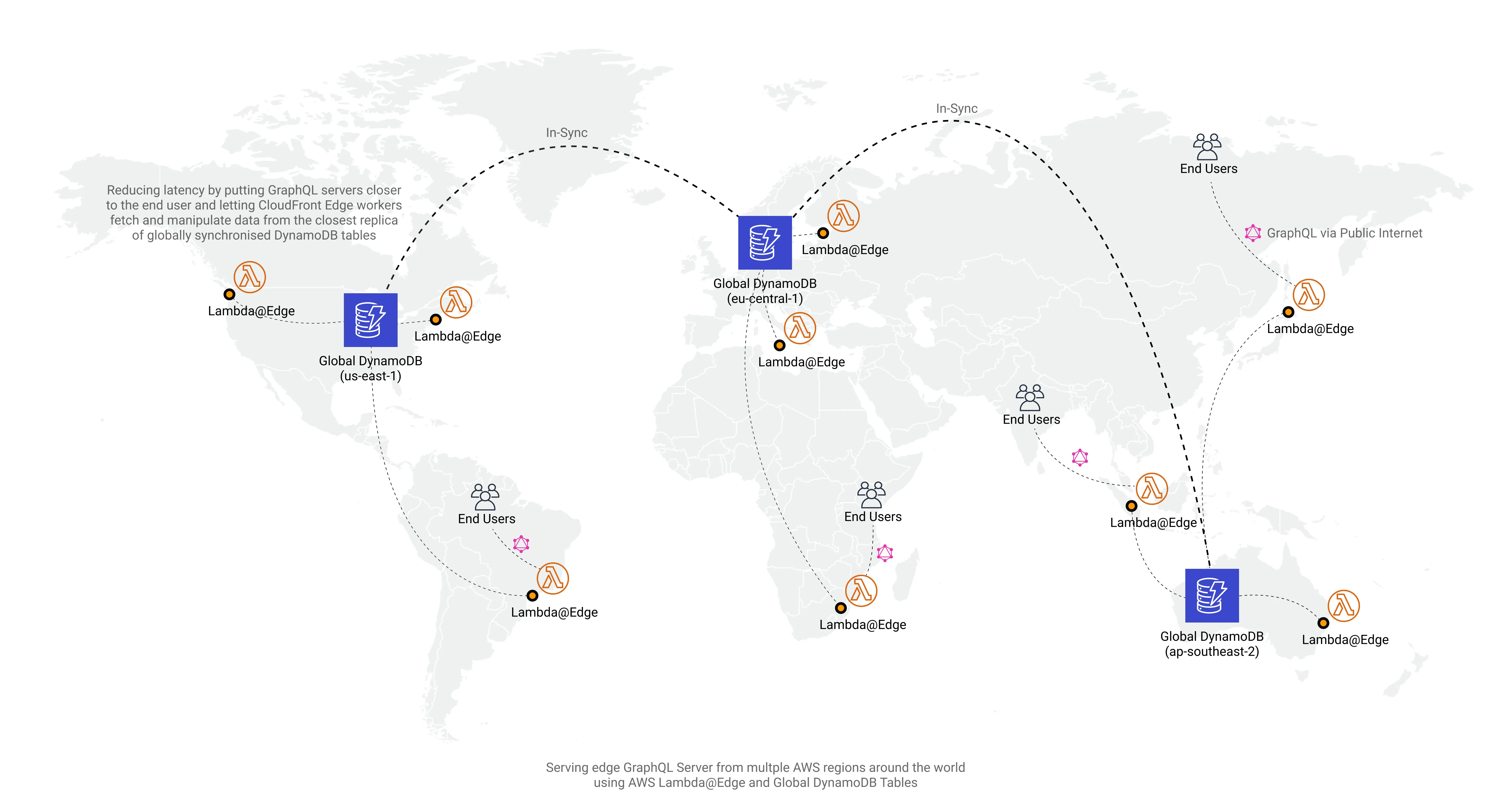
I wanted to explore that problem and see if I can reduce the latency between the end-user and API by deploying a Serverless GraphQL “server” to the each of the CloudFront CDN edge locations using Lambda@Edge and make that work with globally replicated DynamoDB table.
Here’s how I imagined it:

Essentially, each user around the globe instead of hitting that one central endpoint in us-east-1 would be routed to the one of the closest GraphQL “servers” and that “server” would fetch the data from closest globally replicated DynamoDB table using the optimized route.
Since I’m not a big fan of AWS Console, just like many people, I decided to make use of AWS’ new way of provisioning infrastructure, the Cloud Development Kit (CDK).
With CDK, provisioning something which might seem complicated like this example, can actually be done with less than 100 lines of code. Here’s the complete infrastructure code proof of concept explained step by step:
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, "globdynamodb", { partitionKey: { name: "hashKey", type: AttributeType.STRING }, replicationRegions, }); }}First, we provision a [DynamoDB]((https://dynobase.dev/dynamodb/) table with replicationRegions parameter. This creates a multi-master NoSQL database with replicas located in desired regions. For the sake of example, I will be using table with simple string partition key called just hashKey.
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, "globdynamodb", { partitionKey: { name: "hashKey", type: AttributeType.STRING }, replicationRegions, });
const bucket = new Bucket(this, "bucket", { publicReadAccess: true, websiteIndexDocument: "playground.html", }); }}Then, provision an , which will be an origin for CloudFront distribution and will host GraphQL Playground, a web-IDE which makes interaction with GraphQL APIs much easier.
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, 'globdynamodb', { partitionKey: { name: 'hashKey', type: AttributeType.STRING }, replicationRegions, });
const bucket = new Bucket(this, 'bucket', { publicReadAccess: true, websiteIndexDocument: 'playground.html', });
const graphql = new NodejsFunction(this, 'lambda', { entry: './src/graphql-server/dist/function.js', handler: 'handler', memorySize: 128, // Max minify: true, // To fit below 1MB code limit timeout: Duration.millis(5000), // Max role: new Role(this, 'AllowLambdaServiceToAssumeRole', { assumedBy: new CompositePrincipal( new ServicePrincipal('lambda.amazonaws.com'), new ServicePrincipal('edgelambda.amazonaws.com') ), managedPolicies: [ ManagedPolicy.fromManagedPolicyArn( this, 'gql-server-managed-policy', 'arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole' ), ], }), }); }}Next, add a Serverless function with maximum limits for a Lambda@Edge with VIEWER_REQUEST type. Code for this Lambda will be stored inside /src/graphql-server/ directory. We also attach a standard managed IAM policy which allows uploading logs to CloudWatch.
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, 'globdynamodb', { partitionKey: { name: 'hashKey', type: AttributeType.STRING }, replicationRegions, });
const bucket = new Bucket(this, 'bucket', { publicReadAccess: true, websiteIndexDocument: 'playground.html', });
const graphql = new NodejsFunction(this, 'lambda', { entry: './src/graphql-server/dist/function.js', handler: 'handler', memorySize: 128, // Max minify: true, // To fit below 1MB code limit timeout: Duration.millis(5000), // Max role: new Role(this, 'AllowLambdaServiceToAssumeRole', { assumedBy: new CompositePrincipal( new ServicePrincipal('lambda.amazonaws.com'), new ServicePrincipal('edgelambda.amazonaws.com') ), managedPolicies: [ ManagedPolicy.fromManagedPolicyArn( this, 'gql-server-managed-policy', 'arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole' ), ], }), }); }}One weird thing that you may notice here is that I’m using dist/function.js as the entry parameter of the function. This is because when I’m writing this, there’s a bug in NodejsFunction construct which packages dependencies incorrectly.
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, 'globdynamodb', { partitionKey: { name: 'hashKey', type: AttributeType.STRING }, replicationRegions, });
const bucket = new Bucket(this, 'bucket', { publicReadAccess: true, websiteIndexDocument: 'playground.html', });
const graphql = new NodejsFunction(this, 'lambda', { entry: './src/graphql-server/dist/function.js', handler: 'handler', memorySize: 128, // Max minify: true, // To fit below 1MB code limit timeout: Duration.millis(5000), // Max role: new Role(this, 'AllowLambdaServiceToAssumeRole', { assumedBy: new CompositePrincipal( new ServicePrincipal('lambda.amazonaws.com'), new ServicePrincipal('edgelambda.amazonaws.com') ), managedPolicies: [ ManagedPolicy.fromManagedPolicyArn( this, 'gql-server-managed-policy', 'arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole' ), ], }), });
table.grantFullAccess(graphql); }}Out of the box, our Lambda function does not have sufficient permissions to read and write from DynamoDB table. To fix that, we can use grantFullAccess, which permits all DynamoDB operations ("dynamodb:*") to an IAM principal. This one-liner is much more convenient than specifying a custom IAM Role/Policy which iterates through the list of provisioned tables.
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, 'globdynamodb', { partitionKey: { name: 'hashKey', type: AttributeType.STRING }, replicationRegions, });
const bucket = new Bucket(this, 'bucket', { publicReadAccess: true, websiteIndexDocument: 'playground.html', });
const graphql = new NodejsFunction(this, 'lambda', { entry: './src/graphql-server/dist/function.js', handler: 'handler', memorySize: 128, // Max minify: true, // To fit below 1MB code limit timeout: Duration.millis(5000), // Max role: new Role(this, 'AllowLambdaServiceToAssumeRole', { assumedBy: new CompositePrincipal( new ServicePrincipal('lambda.amazonaws.com'), new ServicePrincipal('edgelambda.amazonaws.com') ), managedPolicies: [ ManagedPolicy.fromManagedPolicyArn( this, 'gql-server-managed-policy', 'arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole' ), ], }), });
table.grantFullAccess(graphql);
const graphqlVersion = graphql.addVersion( ':sha256:' + sha256('./src/graphql-server/function.ts') ); }}To make deploying faster, we can tell CDK to update the function only if sha256 of its source code has changed.
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, 'globdynamodb', { partitionKey: { name: 'hashKey', type: AttributeType.STRING }, replicationRegions, });
const bucket = new Bucket(this, 'bucket', { publicReadAccess: true, websiteIndexDocument: 'playground.html', });
const graphql = new NodejsFunction(this, 'lambda', { entry: './src/graphql-server/dist/function.js', handler: 'handler', memorySize: 128, // Max minify: true, // To fit below 1MB code limit timeout: Duration.millis(5000), // Max role: new Role(this, 'AllowLambdaServiceToAssumeRole', { assumedBy: new CompositePrincipal( new ServicePrincipal('lambda.amazonaws.com'), new ServicePrincipal('edgelambda.amazonaws.com') ), managedPolicies: [ ManagedPolicy.fromManagedPolicyArn( this, 'gql-server-managed-policy', 'arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole' ), ], }), });
table.grantFullAccess(graphql);
const graphqlVersion = graphql.addVersion( ':sha256:' + sha256('./src/graphql-server/function.ts') );
const distribution = new CloudFrontWebDistribution(this, 'MyDistribution', { originConfigs: [ { s3OriginSource: { s3BucketSource: bucket, originAccessIdentity: new OriginAccessIdentity(this, 'cloudfront-oai'), }, behaviors: [ { isDefaultBehavior: true, allowedMethods: CloudFrontAllowedMethods.ALL, lambdaFunctionAssociations: [ { eventType: LambdaEdgeEventType.VIEWER_REQUEST, lambdaFunction: graphqlVersion, }, ], }, ], }, ], }); }}The last step is to provision CloudFront CDN with an S3 bucket as an origin and a function from the previous step as an interceptor of viewer requests.
export class GraphQLAtEdge extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props);
const table = new Table(this, 'globdynamodb', { partitionKey: { name: 'hashKey', type: AttributeType.STRING }, replicationRegions, });
const bucket = new Bucket(this, 'bucket', { publicReadAccess: true, websiteIndexDocument: 'playground.html', });
const graphql = new NodejsFunction(this, 'lambda', { entry: './src/graphql-server/dist/function.js', handler: 'handler', memorySize: 128, // Max minify: true, // To fit below 1MB code limit timeout: Duration.millis(5000), // Max role: new Role(this, 'AllowLambdaServiceToAssumeRole', { assumedBy: new CompositePrincipal( new ServicePrincipal('lambda.amazonaws.com'), new ServicePrincipal('edgelambda.amazonaws.com') ), managedPolicies: [ ManagedPolicy.fromManagedPolicyArn( this, 'gql-server-managed-policy', 'arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole' ), ], }), });
table.grantFullAccess(graphql);
const graphqlVersion = graphql.addVersion( ':sha256:' + sha256('./src/graphql-server/function.ts') );
const distribution = new CloudFrontWebDistribution(this, 'MyDistribution', { originConfigs: [ { s3OriginSource: { s3BucketSource: bucket, originAccessIdentity: new OriginAccessIdentity(this, 'cloudfront-oai'), }, behaviors: [ { isDefaultBehavior: true, allowedMethods: CloudFrontAllowedMethods.ALL, lambdaFunctionAssociations: [ { eventType: LambdaEdgeEventType.VIEWER_REQUEST, lambdaFunction: graphqlVersion, }, ], }, ], }, ], });
(distribution.node.defaultChild as CfnDistribution).addOverride([ 'Properties', 'DistributionConfig', 'DefaultCacheBehavior', 'LambdaFunctionAssociations', '0', 'IncludeBody' ].join('.'), true); }}Actually, there’s one more thing. Because as I’m writing this, LambdaFunctionAssociation does not support includeBody parameter. We need to use CDK’s escape hatch to modify synthesized CloudFormation template manually. This is really useful if we want to use some CFN functionality that hasn’t been added to the CDK yet.
If you don’t like this animation, checkout full source at Github. You can play with it using mentioned GraphQL Playground here.
What’s great about this solution is:
- It’s completely Serverless. Costs me nothing if it’s not used. I’m billed on data stored, read and transferred basis
- It’s highly available on all levels, from data layer up to the public endpoint(s)
- It’s fast, apart from cold-starts
- Thanks to CDK and jsii, application code and infrastructure definition is written in one language. This reduces the amount of context shifts and reduces the cognitive load on devs. You can do that with C#, Java, and Python too, because CDK supports all of them
- Maintaining or modifying it is a breeze. Creating the same solution using CloudFormation or Terraform would take x5 amount of code
But not it’s definitely not ideal, there are some very important cons:
- Your
serverGraphQL endpoint must be lightweight. Minified Lambda@Edge code must be less than 1 MB. Moreover, it is restricted to128MBof memory and5000msof execution time forVIEWER_REQUESTintegration type. Definitely not usable for heavy computation because Lambda computing power is scaling with allocated memory - Cannot use environment variables with Lambda@Edge
- It’s using low-level GraphQL.js library where schema creation is tedious; I wasn’t able to deploy fully-featured Apollo Server, which is standard in Node.js world. It’s hard to keep it under
1MBcode limit and under128MBmemory usage limit - DynamoDB Global tables are eventually consistent. In a global table, data modifications are usually propagated to all replica tables within a second. It is a deal-breaker for many use cases. They also cost much more because you also pay for Replicated write request units and it scales linearly with the amount of table replicas.
Concluding - is it useful?
Might be for some very specific use cases. Right now, due to Lambda@Edge limitations - not really. With imposed restrictions, it disallows creating any serious logic. But, I hope these will change in the future. AWS is developing its FaaS offering very actively, continually making it better. For now, if I will need to create a Serverless GraphQL API, I’ll probably stick to AppSync.
Found this insightful? If you're interested in my AI consulting, please reach out to me via email or on X